
Chat GPT is basically Chat + GPT or Generative Pretrained Transformer. All these text to text AI models are basically TRANSFORMERS. And now, because you guys are babies, I know what you guys are thinking, those cars that can convert into robots right!? NOOOOOO! Grow up!
In the world of AI, a transformer is a type of neural network architecture that has excelled in tasks involving sequential data, like NATURAL LANGUAGE PROCESSING or NLP for short (what Chat GPT does), Image Recognition, Speech Recognition.
Now, I know, words like neural network, architecture, sequential data can be a little overwhelming, like trying to understand alien language so, in simple words, Chat GPT is nothing but a Transformer (a type of AI Model) that is Pre-trained (Meaning, it's already trained by the company which made it, and we don't need really need to train it before using it although, we can if want to) on some data and can Generates responses based on user's prompts. SIMPLE!
Now, we know if we want to know working of Chat GPT, we need to know how Transformers work. Let me give you a cool analogy to make it easy: Imagine you're trying to translate a book.
Traditionally, you'd read a sentence, then translate it, then move on to the next. It's like building a wall, brick by brick.
Transformers are like super-smart translators that can look at the entire book at once. They can see how every word relates to every other word, kind of like a bird's-eye view. This lets them understand the context better and make more accurate translations. It's like having a super-powered brain that can process information in a way humans can't.
To perform a translation type of NLP task, transformer performs few processes at some crazy speeds. Disclaimer, things will go a little complex, however, I will not introduce any crazy mathematics behind it but babies should buckle up! Let's discuss those tasks:
- Encoding
- First, we convert our input words into numbers (vectors/matrix) that the computer can understand. Think of this as giving each word a unique ID. This is called Input Embedding.
- Since transformers process all words at once (unlike humans who read left to right), we need to tell the model the position of each word. We add special "position numbers" to each word's ID. This helps the model understand word order. This is called Positional Encoding.
- After, this comes heart of transformer called Self-Attention. We will not understand it's working in this blog as it can get a little complex, but in simple words, it's like having each word look at all other words and decide how important they are to its meaning.
- This comes under Multi-Head Attention Block in which we repeat the self-attention process multiple times in parallel. This allows the model to focus on different aspects of the relationships between words.
- After self-attention, we add the original input back (like a shortcut connection) and then normalize the results. This helps stabilize the learning process and allows for deeper networks. This process is called Layer Normalization.
- Now, each word then goes through its own small neural network (Basically an AI Model). This helps the model learn more complex patterns and relationships. These small neural network or AI model is called Feed-Forward Network.
- We again add the input from before to the feed-forward network and normalize. (Basically, performing Layer Normalization again.)
- Decoding
- The decoder takes the output sequence, shifted right by one position. The first token is a special "start of sequence" token. It converts each token in this sequence into a numerical representation (vector). Which are called Output Embeddings.
- Like encoder, it adds information about the position of each token in the sequence or we can say it performs Positional Encoding again.
- Next layer is nothing but a Multi-head attention layer, but with a mask that prevents it from looking at future tokens. It helps understand the context of each token based on previous tokens. This is called Masked Multi-Head Attention.
- We again add the original input to the output of the attention layer and normalize the result.
- Now comes the best part, Cross-Attention Block, this is where the decoder connects with the encoder. It uses the output from the encoder to focus on relevant parts of the input sequence for each decoding step.
- We repeat step mentioned in point 2.4
- After this, another Feed-Forward Network comes in between.
- Finally, we repeat step mentioned in point 2.4 last time.to normalize the output.
- Predicting
- Finally, we use a Linear layer to convert our processed information into probabilities for each word in our vocabulary.
- And after applying Softmax activation layer we know, which is the most likely next word.
This entire process is repeated multiple times (multiple layers) to create a deep network that can understand and generate complex language patterns.
We can understand these connection with the figure below:
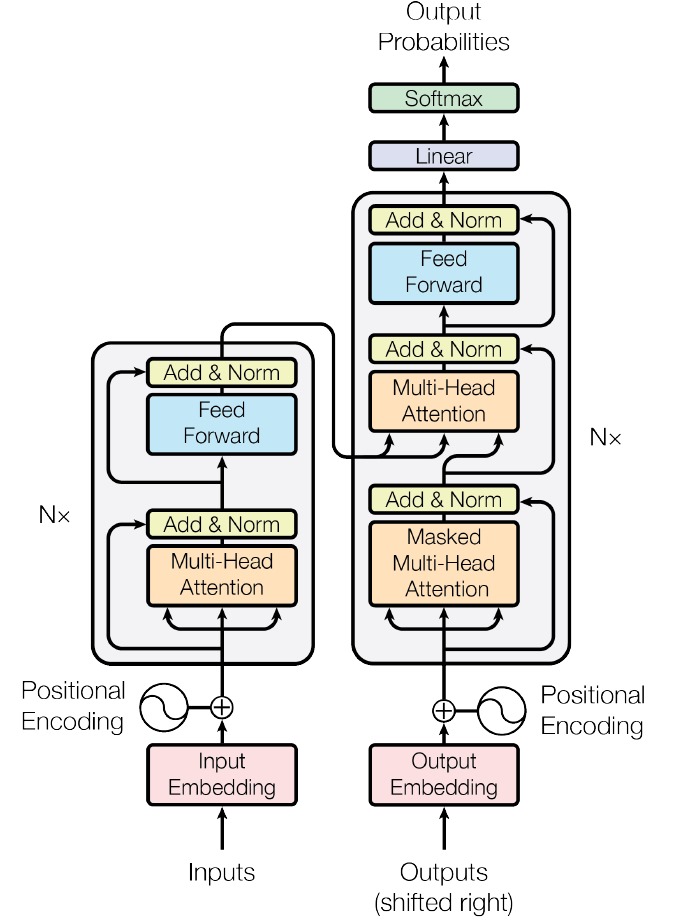
FIG 1(Pictorial Depiction of structure of transformer)
Now, this model will piece by piece predict each and every word and then give output to the user, which is translation. But, before that we need to perform a very important step, called training. For example, if you want to translate to Spanish from English, you will need a dataset that has data of English Sentences translated to Spanish. Transformer will automatically learn from dataset and will translate your English input to Spanish.
Wow!!, you were able to finish this blog? DAMNN!!! It's my honor to make you aware that you are finally a teenager now!! BUT, if you want turn into an adult, you need to learn how everything is working mathematically and what actually is happening with stuff in this transformer. For that you should refer below stated references for a better understanding of a Transformer.
References
- Transformer Neural Networks Video by CodeEmporium - High level understanding of main ideas of Transformer
- The Illustrated Transformer - A great introduction to Transformer with helpful illustrations to build intuition
- Transformers from scratch - Extremely good post that goes into much depth
- Attention Is All You Need Research Paper that introduced attention mechanism, this whole blog is basically a high level simplification of this research paper.
- On the Expressivity Role of LayerNorm in Transformers' Attention, Explains why Layer Normalization helps self attention.
- Positional Encoding by Amirhossein Kazemnejad Explains the math and intuition behind positional encoding